INTRODUCING HAZELCAST JET – A NEW LIGHTWEIGHT, DISTRIBUTED DATA PROCESSING ENGINE
27-02-2017
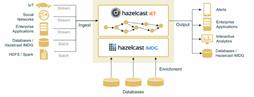
Hazelcast, the leading open source in-memory data grid (IMDG) with hundreds of thousands of installed clusters and over 17 million server starts per month, today launched Hazelcast Jet – a distributed processing engine for big data streams. With Hazelcast’s IMDG providing storage functionality, Hazelcast Jet is a new Apache 2 licensed open source project that performs parallel execution to enable data-intensive applications to operate in near real-time. Using directed acyclic graphs (DAG) to model relationships between individual steps in the data processing pipeline, Hazelcast Jet is simple to deploy and can execute both batch and stream-based data processing applications. Hazelcast Jet is appropriate for applications that require a near real-time experience such as sensor updates in IoT architectures (house thermostats, lighting systems), in-store e-commerce systems and social media platforms.
IoT devices churn out massive amounts of data which flows to computers for analysis. In some cases, analyses must be done in near real-time – log analysis, monitoring, fraud detection, dashboard data extraction, and placement. However, there are challenges to handling large amounts of data:
Ingest high volumes of data, while keeping up-to-date with what’s coming in;
Anomaly detection, recognize and validate the correctness of data entering the system;
Analyze, aggregate, extrapolate and react to a situation in near real-time;
Work with extremely low latency access to data; and
Reporting, whether running on-demand or via scheduled batch processing.
Hazelcast Jet is built on top of a one-record-per-time architecture (sometimes known as continuous operators). This means that it processes incoming records as soon as possible, opposed to accumulating records into micro-batches, consequently lowering latency for applications. Jet ingests data at high-velocity (via socket, file, HDFS or Kafka interfaces), and processes the business logic or complex computation on incoming data. A pure in-memory approach, Jet is 20x faster than Hadoop, enabling users to meet service-level requirements. It is extremely simple to program and to deploy – in particular Jet can be fully embedded for OEMs and for Microservices – making it is easier for manufacturers to build and maintain next generation systems.
Important components include:
Events-based architecture for low latency Transaction Processing System (TPS) applications
Uses directed acyclic graphs (DAG) to model data flow
High level util.stream API for great simplicity.
Low level Core (DAG) API for maximum flexibility allowing direct manipulation of vertices representing data source readers, joiners, sorters, aggregators and data sinks
Distributed connectors for reading and writing: Hazelcast IMDG Map and List, HDFS, Kafka, File, Socket
Greg Luck, CEO of Hazelcast, said: “Hazelcast Jet is a super fast, low latency, next generation DAG Engine for Big Data processing. We believe that the Hadoop and Spark ecosystems are too complex to program and to deploy and have set out to bring Hazelcast’s legendary simplicity to Big Data. We have designed it as a general purpose engine for the intersect of Big Data programmers and Java programmers. But if you are already a Hazelcast user or have data in Hazelcast it will be the easiest way to solve your Big Data problems. ”
Hazelcast will be providing 24×7 enterprise support subscriptions for Hazelcast Jet.